Ever heard of Internet archives? Introducing you to the website WayBack Machine
2018.09.19
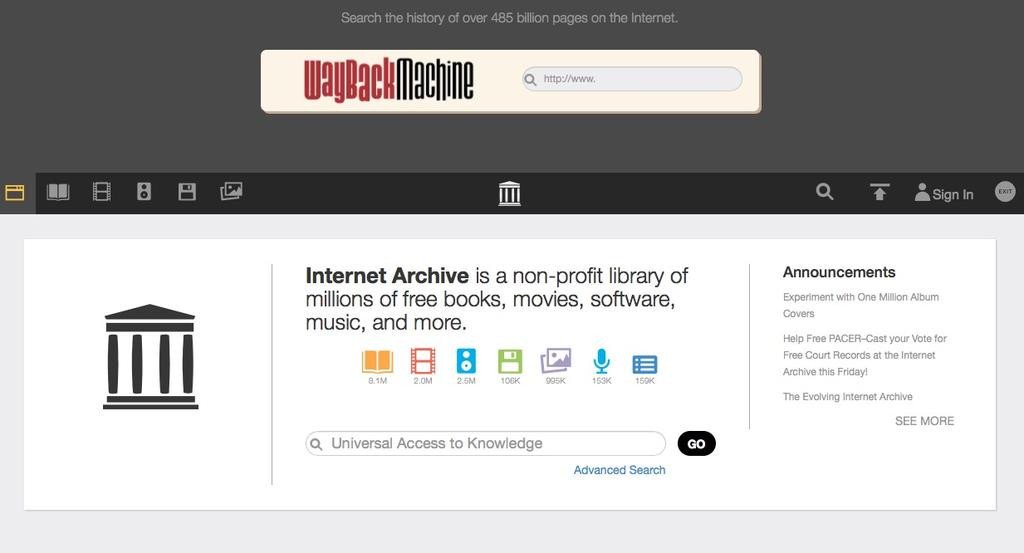
"This article will be introducing everyone the website ‘WayBack Machine’. WayBack Machine is basically an Internet archive that contains a lot of online data that no longer exist. A lot of content not even Google can find is made available on WayBack Machine so you’d have a chance to find them. Those who may be interested, come to take a look!"
We have museums to collect artefacts, libraries to store old books, then, of course, there are organisations that specialise in “storing websites”. The WayBack Machine shown in the above image is a website that specialises in storing web data. Whether it is websites that still exist or ones that have been closed down. Not only can you find the sites, but there is also a chance for you to find a particular webpage or even its media content!
 Before we learn about this website’s history, let’s look at how competent WayBack Machine actually is. Today I am using “wretch” as a search example, it was what once was the pride of Taiwan but unfortunately ended its service eventually. However, I really don’t remember which blogs I can search (I myself never used wretch), so I’ll be using wretch celebrity “Wan Wan” as today’s test subject. After some vigorous research (I deleted this from my favourites long ago!), I was able to find the link that once led to Wan Wan’s blog, “www.wretch.cc/blog/cwwany”.
Before we learn about this website’s history, let’s look at how competent WayBack Machine actually is. Today I am using “wretch” as a search example, it was what once was the pride of Taiwan but unfortunately ended its service eventually. However, I really don’t remember which blogs I can search (I myself never used wretch), so I’ll be using wretch celebrity “Wan Wan” as today’s test subject. After some vigorous research (I deleted this from my favourites long ago!), I was able to find the link that once led to Wan Wan’s blog, “www.wretch.cc/blog/cwwany”.
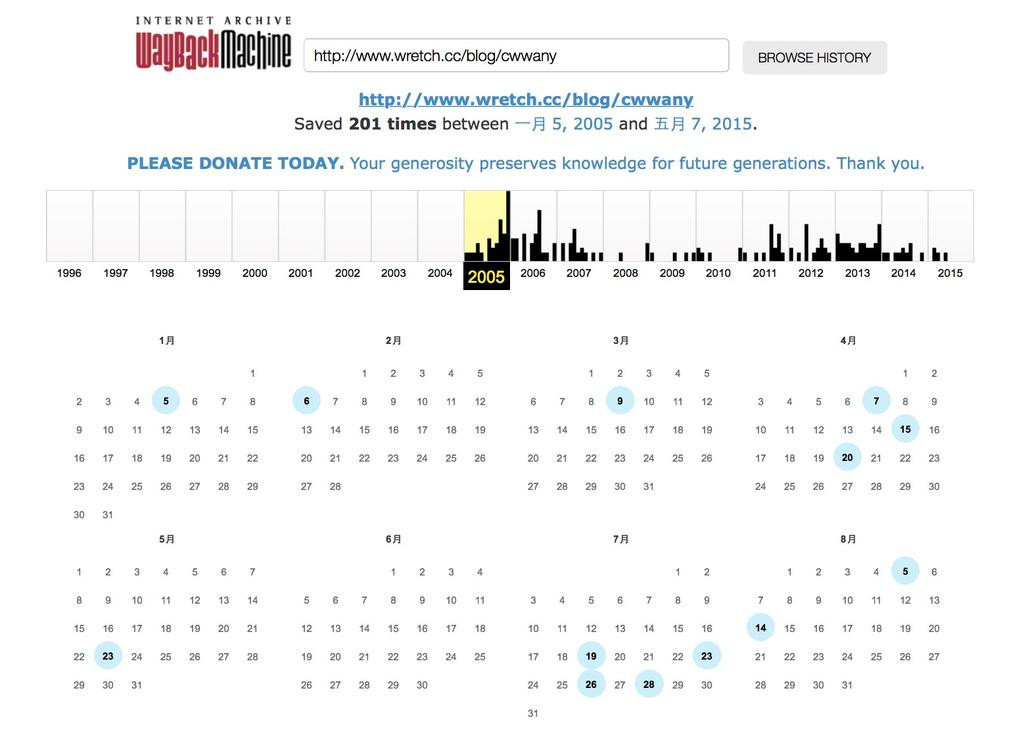
 After entering this in the search bar, Wayback Machine will start searching the past saves of this website (they never delete outdated stuff). But don’t think that Wayback Machine will help you make daily backups, there is, after all, a very large amount of data on the internet (in 2012 there is around 10PB of information stored in Wayback Machine, which equals to around ten million GB), therefore the results of your searches will only appear like as shown in the above picture, only the dates circled in blue are dates where a backup was made.
Note: Wan Wan’s blog attracts huge traffic, which means that it gets backed up often. If your blog has little traffic… then it probably was only backed up once or twice
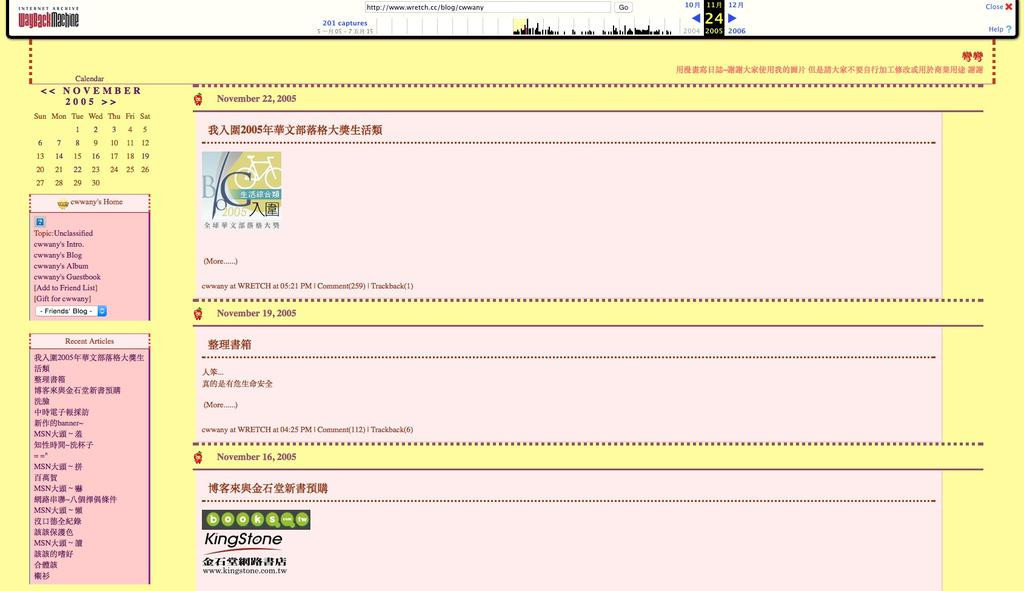
Now let’s go ahead and check on a random date… and check out the web data saved in the past! Seeing once again this historic scene today where wretch no longer exists sure is making me nostalgic! But limited by Wayback Machine’s processing power and limitation of the website itself, the pictures that used to be on the blog are all long gone. You are therefore unable to see the collection of Wan Wan’s comics, so this is really only useful for nostalgic purposes. However, this means that text-based web pages are not limited by this, so if you’re only seeking text content from text-heavy websites then this truly is a useful tool.
After entering this in the search bar, Wayback Machine will start searching the past saves of this website (they never delete outdated stuff). But don’t think that Wayback Machine will help you make daily backups, there is, after all, a very large amount of data on the internet (in 2012 there is around 10PB of information stored in Wayback Machine, which equals to around ten million GB), therefore the results of your searches will only appear like as shown in the above picture, only the dates circled in blue are dates where a backup was made.
Note: Wan Wan’s blog attracts huge traffic, which means that it gets backed up often. If your blog has little traffic… then it probably was only backed up once or twice
Now let’s go ahead and check on a random date… and check out the web data saved in the past! Seeing once again this historic scene today where wretch no longer exists sure is making me nostalgic! But limited by Wayback Machine’s processing power and limitation of the website itself, the pictures that used to be on the blog are all long gone. You are therefore unable to see the collection of Wan Wan’s comics, so this is really only useful for nostalgic purposes. However, this means that text-based web pages are not limited by this, so if you’re only seeking text content from text-heavy websites then this truly is a useful tool.
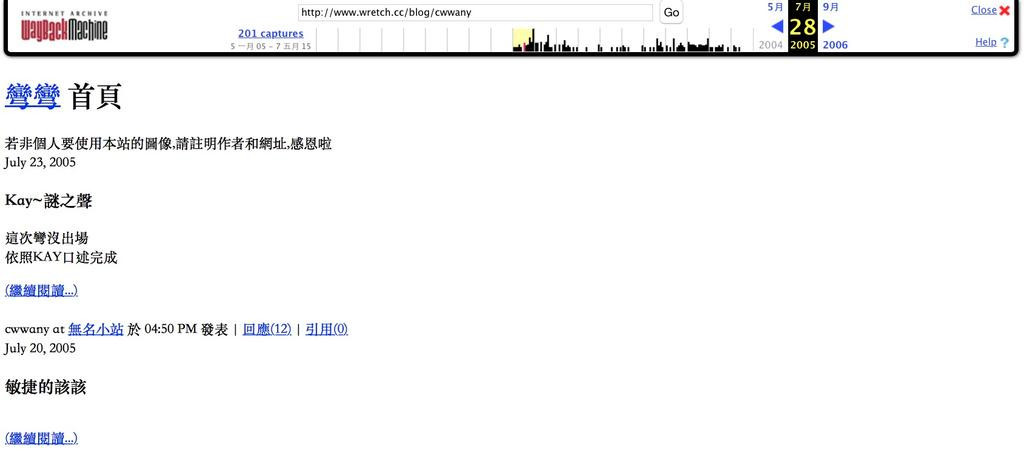 For some of the dates, the crawler may be bugged, resulting in the website not being properly backed up, leaving only its basic text data. But don’t despair, since every backup is theoretically “a complete website backup”, you could actually click on a webpage that is better preserved (such as Wan Wan’s blog in the example above), and searches for your other desired pages from the said webpage. For instance, the works of mAn does not show to have backups on any of the indicated dates on the schedule, but actually you just need to go to any of the indicated points (after 2010/09/01) and go to web archive, you will be able to to find mAn’s content through these saves.
Note: This website is very slow. It is, after all, a non-profit organisation with an enormous amount of data
For some of the dates, the crawler may be bugged, resulting in the website not being properly backed up, leaving only its basic text data. But don’t despair, since every backup is theoretically “a complete website backup”, you could actually click on a webpage that is better preserved (such as Wan Wan’s blog in the example above), and searches for your other desired pages from the said webpage. For instance, the works of mAn does not show to have backups on any of the indicated dates on the schedule, but actually you just need to go to any of the indicated points (after 2010/09/01) and go to web archive, you will be able to to find mAn’s content through these saves.
Note: This website is very slow. It is, after all, a non-profit organisation with an enormous amount of data
 Exactly what are the kind of people running such a “charity” of an organisation?
Wayback Machine actually has a backer called “The Internet Archive”, it is an “ancient internet organisation” established in 1996 in San Francisco. The objective of this organisation is to archive all the information to ever exist on the internet, like a library or a museum, this archive collects historical data and makes them available for users and scholars alike to browse. The Internet Archive is created by the founder of the famous web analysis company Alexa (the same Alexa used for web ranking), when it was just established it was actually one with Alexa, functioning as two organisations (Alexa for profit, The Internet Archive as non-profit).
The company name Alexa pays respects to the Library of Alexandria, making the comparison between the world wide web and the largest library in the world two thousand years ago, the Library of Alexandria. However Alexa was eventually bought by Amazon with 250 million US dollars, and aside from having the same founder, The Internet Archive has nothing to do with Alexa anymore. So far The Internet Archive can save data from after the year 2001 (limited by the technology of Wayback Machine) and is one of the best tools to perform research on the early development of the world wide web.
Note: The Internet Archive is now a member of the American Library Association ALA, and is also appointed as an official library by the State of California.
If you are interested in our articles, you can also LIKE our page:)
Want to see more related articles? CLICK ME to enter the Chinese version website.
Exactly what are the kind of people running such a “charity” of an organisation?
Wayback Machine actually has a backer called “The Internet Archive”, it is an “ancient internet organisation” established in 1996 in San Francisco. The objective of this organisation is to archive all the information to ever exist on the internet, like a library or a museum, this archive collects historical data and makes them available for users and scholars alike to browse. The Internet Archive is created by the founder of the famous web analysis company Alexa (the same Alexa used for web ranking), when it was just established it was actually one with Alexa, functioning as two organisations (Alexa for profit, The Internet Archive as non-profit).
The company name Alexa pays respects to the Library of Alexandria, making the comparison between the world wide web and the largest library in the world two thousand years ago, the Library of Alexandria. However Alexa was eventually bought by Amazon with 250 million US dollars, and aside from having the same founder, The Internet Archive has nothing to do with Alexa anymore. So far The Internet Archive can save data from after the year 2001 (limited by the technology of Wayback Machine) and is one of the best tools to perform research on the early development of the world wide web.
Note: The Internet Archive is now a member of the American Library Association ALA, and is also appointed as an official library by the State of California.
If you are interested in our articles, you can also LIKE our page:)
Want to see more related articles? CLICK ME to enter the Chinese version website.
相關文章
-
The lighting for food is important? Let Tastemade tell you!
-
Here comes the Apple's new iPhone XS and Apple Watch official promoting picture!
-
A more efficiency and safety Chrome is coming after it has been launched a decade.
-
Microsoft Xbox One will soon can be able to voice control by Alexa and Cortana !
-
Facebook wants to stop Internet bullying by using Rosetta!
-
Alexa will be able to provide Skype Internet calling in the future!